
10月 22, 2024
0ChatGPTのアドバンスド・ボイス・モードがEUで利用可能に – 最新情報とアクセス方法
アドバンスド・ボイス・モードがついにEUに登場し、欧州連合(EU)の規制によって設定されていたこれまでの障壁を打ち破った。この会話AIの強化は、よりダイナミックで魅力的な対話体験をもたらします。以下は、新しいアドバンス音声モードと旧バージョンのアシスタントの比較です。 アドバンス音声モードを使用するには、プラスプランに加入し、アプリケーションを最新バージョンにアップデートする必要があります。 *更新:イタリア、ドイツ、スウェーデンのユーザーも、アドバンスド・ボイス・モードが彼らの国でも機能することを確認しています。 *更新2*:アップデート2*: 現在、正式版です: 主な違い – 人間らしい対話:アドバンスモードはより会話的で、対話の自然な流れに合わせますが、ノーマルモードはより機械的に感じられます。 – 文脈への敏感さ:アドバンス音声モードは、文脈に従う能力が高く、特に長い会話や複雑な会話において、ユーザーとのインタラクションを向上させます。 – カスタマイズ:ユーザーは、トーンやスピードなどの音声パラメーターを調整することができ、通常モードにはない、よりパーソナライズされた対話を提供します。 詳しい比較はこちら: 特徴 アドバンス音声モード 通常モード 音声対話の質 人間のような、より自然なイントネーションと応答 ロボットのような基本的な音声対話 会話の流れ よりスムーズで、自然な間への反応 標準的なポーズ、よりダイナミックな応答 文脈認識 改善され、文脈をより効率的に記憶 応答間のコンテキストの保持は限定的 カスタマイズオプション 声のトーン、ペース、スタイルのカスタマイズが可能 音声調整のオプションは限定的、またはなし 音声認識 さまざまなアクセントや発話パターンを認識する能力が強化されています。 標準的な音声認識 多言語サポート 音声対話におけるさまざまな言語の幅広いサポート 基本的な機能を持つ主要言語に限定 音声コマンド…

六月 13, 2024
0アップルがSiriにGPT-4oを統合するためにOpenAIに支払う代償は?$0.
暴露のために働くことはないとよく言われる。Bloombergの記事によると、アップルのApple Intelligenceの全体的な発表の一部であったChatGPTとSiriの 統合は、まさにそのような計画であった。Bloombergの記事によると、アップルのApple Intelligence全体の発表の一部であるChatGPT-Siriの統合は、まさにその計画なのだという。要するに、彼らはあなたのIP アドレスとその他の識別子をカバーするので、Open AIはあなたのリクエストを結びつけるためにあなたのプロファイルを構築することはできません。 彼らが意図的に開示しなかったのは、パートナーシップの金銭的条件だ。両社にとって有益な相互提携であるため、金銭的な問題はないことが判明した。ChatGPTの名前は、iPhone、MacBook、iPadのさまざまなメニューや設定に表示され、サービス(ファイル処理、より多くの知識、画像生成を可能にする月額20ドルのサブスクリプション層がある)を宣伝する。 一方、アップルは、少なくともアップルが独自のAIモデルをオープンAIと同等にするまでは、他のアップル・インテリジェンス・サービスを助けるために、最高のAIチャットボットを手に入れることになる。アップルはまた、グーグルのGeminiを含む、自社のチャットボットを利用する他の企業との協力にも意欲的だ。アップルは、iPhoneやiPadでサービスを収益化するAI企業と提携することで、新たな収入源を作ろうとしている。
5月 24, 2024
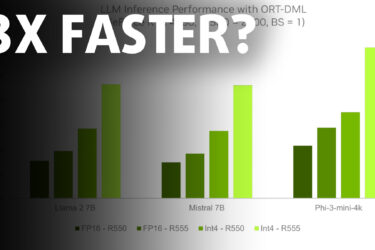
0NVIDIAが新R555版ドライバをリリース、RTXカードの「AI性能」を最大3倍向上させると主張
そう、派手なタイトルは、往々にしてその面目躍如となるものだが、今回、エヌビディアは「AI性能」を実に3倍も向上させた。もちろん、AIパフォーマンスとは具体的に何を指すのか、といった注意点はある。NVIDIAの結果は、AIモデルが1秒間にどれだけのトークン(ライブデータ)を読み取り(プロンプトから)、出力(答えを与える)できるかを測定するために、推論パフォーマンスを使用しています。 NVIDIAのパフォーマンスチャートはONNX ORTを使用しています。ONNXは、技術スタックにAIを大量に実装しようとしている、ほとんどすべての主要企業に支援されているAIコンソーシアムです。すべてのONNXパートナーをここで見つけることができる。ORTはONNX Runtimeの略で、ご想像の通り、さまざまなLLMを実行できるランタイムだ。NVIDIAが3つの異なるLLM、MetaのLlama 2 7B、Mistral 7B、MicrosoftのPhi-3-mini-4kでテストしたことがわかります。すべてのLLMはオープンソースであるため、それらを入手し、特定の目的のためにトレーニングすることができます。 ご覧のように、NVIDIAは4つの異なるドライババージョンを使用し、緑の濃淡が異なります。3倍の性能は、FP16-R550ドライバとInt4 R555ドライバの結果から導き出されたものです。しかし、ここで注意点があります。新しいドライバーはInt4量子化を使用しています。量子化とは、LLM内のデータを単純化することで、より少ないスペースで、より少ないGPU メモリで実行できるようにすることです。これにより性能は向上しますが、出力が不正確になる可能性があります。なぜなら、量子化なし(FP32)、または量子化を少ししか行わない(FP16)場合、データは正確で、変換を受けないからです。Int8またはInt4の量子化に切り替えると、浮動小数点(FP)を削除することになり、これが先ほどお話ししたスペースの節約になります。 つまり、パフォーマンスを向上させる一方で、精度を犠牲にすることになります。RTXチャットを使用している場合、またはスモールタイムLLMを実行している場合、これはGPUリソースを可能な限り節約する有効な方法です。また、多くのメーカーにとって次のステップと思われる、ローカルLLMがモバイル機器内に存在することにもつながるだろう。


![[2026年4月] アマゾングローバル:ノートPC売れ筋トップ10 – HP 14が市場を席巻、低価格機がプレミアム機を上回る](https://laptopmedia.com/wp-content/uploads/2026/05/Best-Selling-Laptops-GLOBAL-Top-10-400x225.jpg)
![[2026年4月] アマゾンで最も売れているノートPCブランド – アップルが60%近い売上シェアを占める](https://laptopmedia.com/wp-content/uploads/2026/05/GLOBAL-Best-Brands-400x225.jpg)
![[2026年4月] アマゾンのノートPC用CPU売れ筋ランキング – インテルが格安市場を独占するも、アップルはM4でプレミアムを制す](https://laptopmedia.com/wp-content/uploads/2026/05/Best-Selling-CPUs-GLOBAL-Top-10-400x225.jpg)

