NVIDIA releases new R555 version drivers, claims to increase “AI performance” up to 3x on RTX cards
Yes, yes flashy titles often fall flat on their face, however, this time NVIDIA does really improve “AI performance” by three times. Of course, there are caveats, like what exactly do they mean by AI performance? NVIDIA’s results use Inference Performance to measure how many Tokens per second (live data) the AI model can read (from your prompt) and output (give an answer).
NVIDIA’s performance chart uses the ONNX ORT. ONNX is an AI consortium backed by pretty much every major corporation that’s looking to heavily implement AI in its tech stack. You can find every ONNX partner here. ORT stands for ONNX Runtime, and it’s the, you guessed it, the runtime on which you can run different LLMs. You can see that NVIDIA has tested on three different LLMs, Meta’s Llama 2 7B, Mistral 7B, and Microsoft’s Phi-3-mini-4k. All the LLMs are open sourced so you can get them and train them for a specific reason.
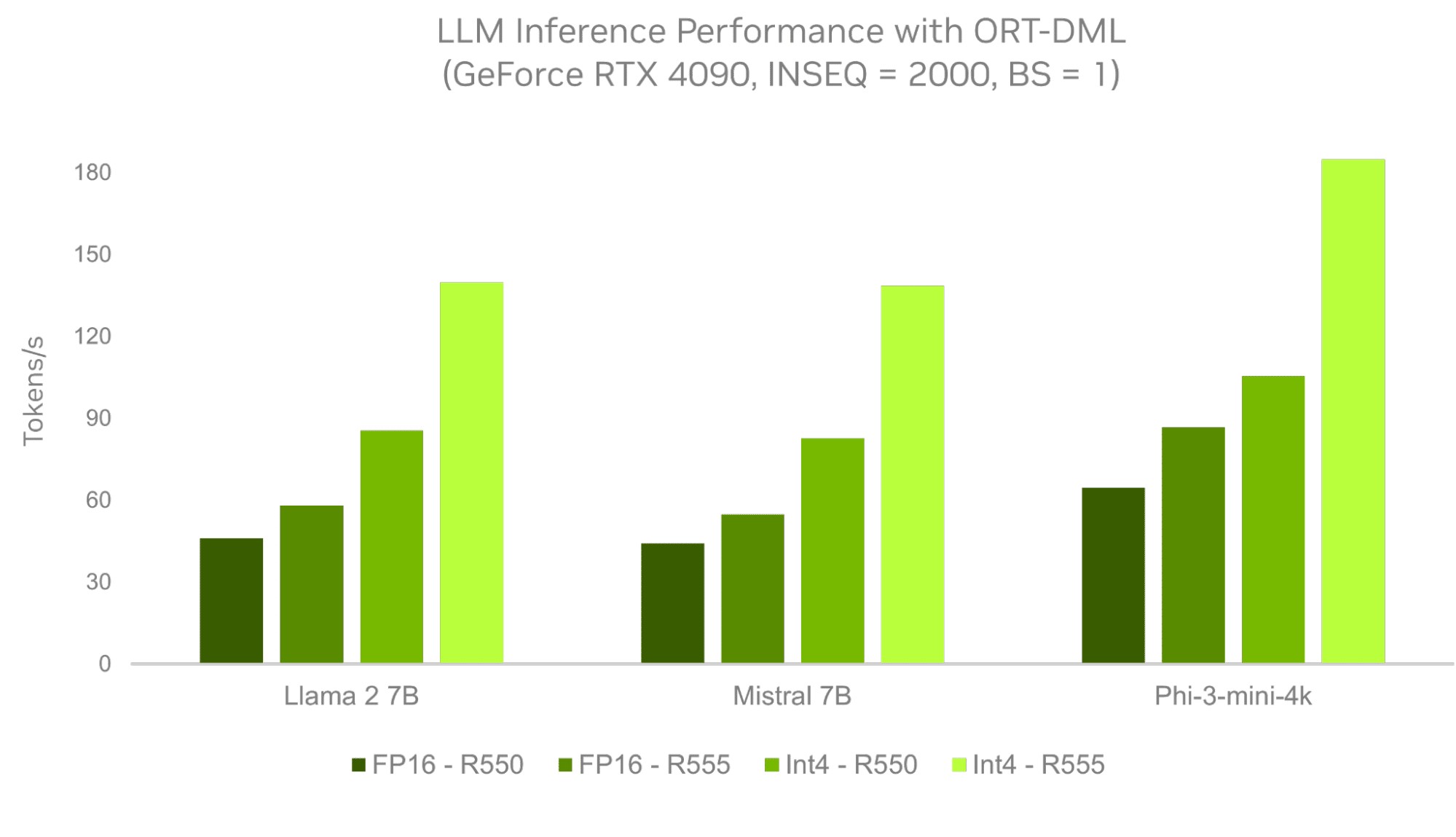
As you can see, NVIDIA used four different driver versions, varying in shades of green. The 3X Performance is derived from the results of the FP16-R550 driver versus the Int4 R555 driver. But here comes the caveat. The new driver uses Int4 Quantization. Quantization is the simplification of data in a LLM so that it takes less space and requires less GPU memory to run. This increases performance but can lead to inaccuracies in the outputs. This is because, without Quantization (FP32) or with little Quantization (FP16), the data is as accurate and doesn’t partake in any transformation. When switching to Int8 or Int4 quantization, you’re removing the floating point (FP), which is the space-saving that we talked about.
So while you’re gaining performance, it’s at the cost of accuracy. While using RTX Chat or running a small-time LLM, this can be a neat way of sparing as much GPU resources as possible, so you can also game, while the AI is doing its thing. It will also inadvertently lead to local LLMs being present inside mobile devices, which seems like the next step for many manufacturers.